array list와 다르게 메모리에 저장될 때 나란히 저장되지 않을 수 있다.
그래서 인덱스가 노드마다 지정되어있지 않음
Big(O)
linked list에서 n은 노드의 수라고 생각하면 된다.
append(adding sth to the end)
노드가 몇개이든 바뀌는 게 없음
⇒ 0(1)
remove last node
linked list의 연결 방향은 반대로 가는 게 불가능
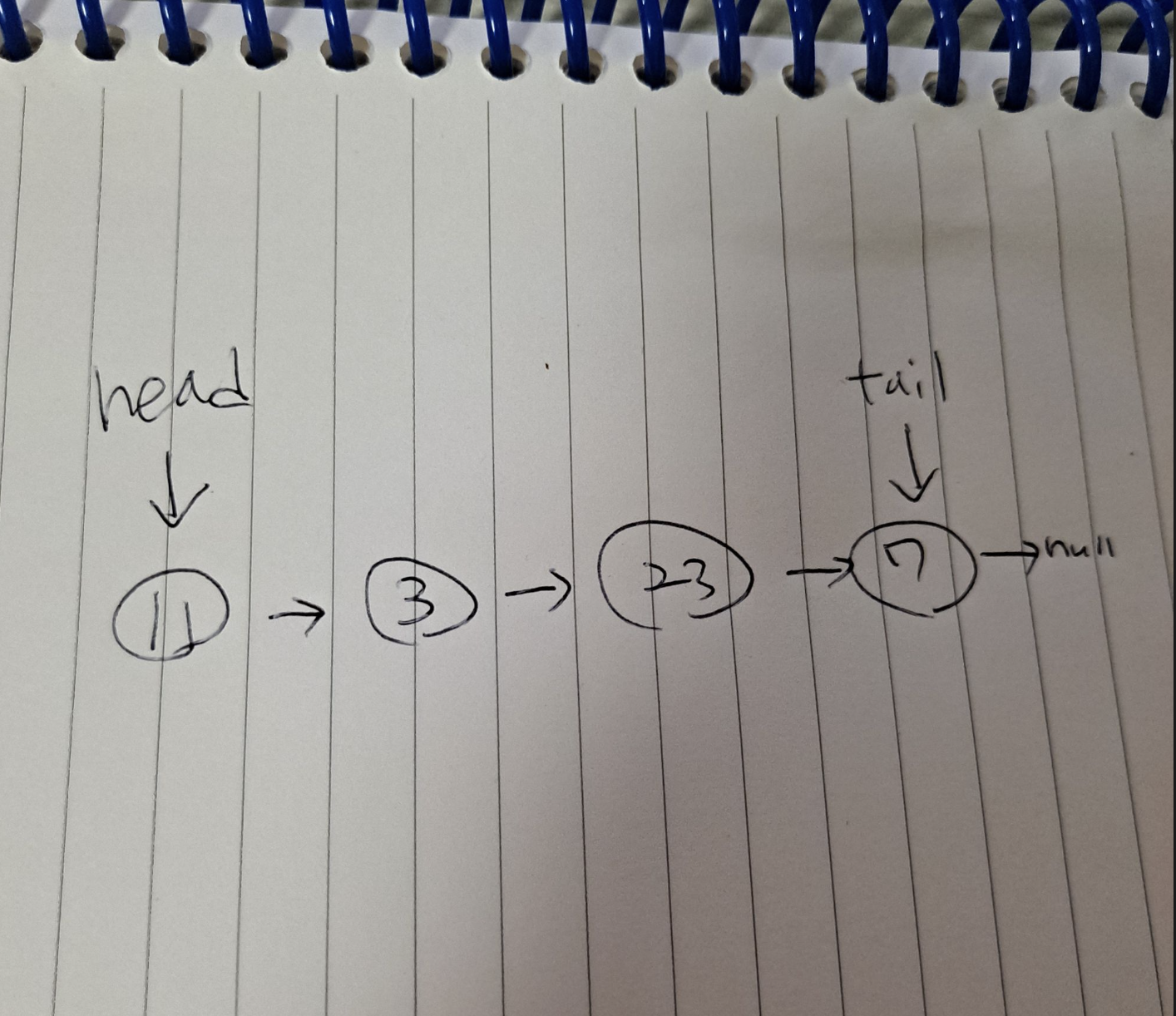
예를 들면 여기서 7 노드를 없앤다면 tail을 23 노드로 옮겨야 하는데
반대로 추적할 수 없기 때문에 head부터 반복문을 돌려서 마지막 노드를 찾아야 함.
n이 클수록 반복문 돌려야 하는 횟수도 늘어나기 때문에
⇒ O(n)
remove first
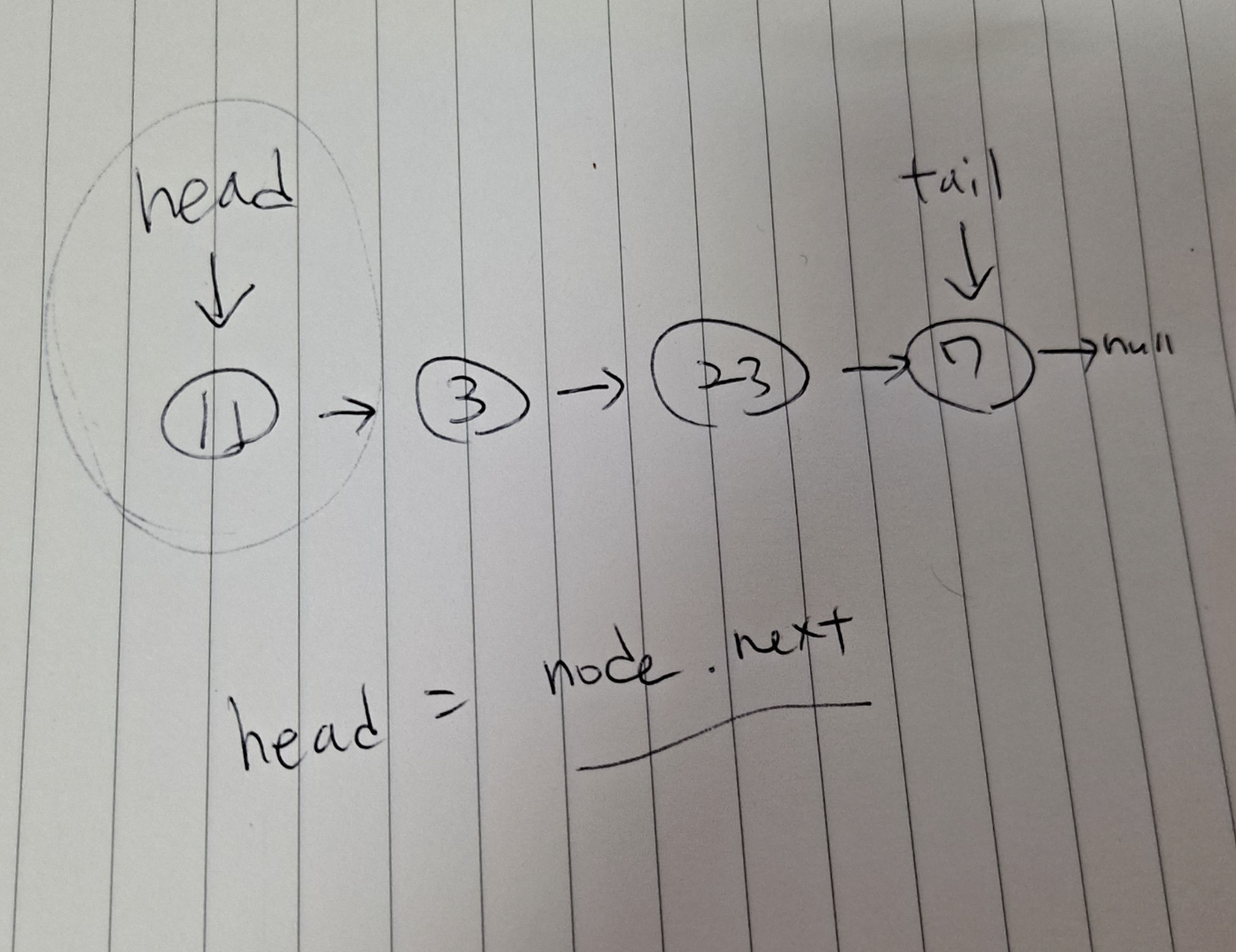
여기서 11 노드를 삭제한다고 하면 head를 11노드 다음에 있는 노드로 옮기고 11노드를 삭제하면 된다. 노드가 몇 개이든 이 과정은 한 번만 이루어지기 때문에
=> O(1)
prepend
위와 같은 원리로
⇒ 0(1)
insert
23과 7 사이에 4를 넣으려고 한다
23까지 반복문 돌려서 간다음에
23에서 7을 가리키는 포인터를 4에게 줌
그리고 23은 4를 가리키게
=> 0(n)
remove
위와 비슷한 원리로
=> 0(n)
조회할 때
값으로 찾으나 인덱스로 찾으나 둘 다 반복문 돌아가면서 찾아야 함
=> 0(n)
이것만 보면 어레이 리스트가 훨 나음
그러나 prepend와 remove first에서는 linked list가 0(1), arraylist가 0(n)으로 더 낫다.
linked list에는 index가 없기 때문
arraylist는 요소들이 추가되거나 삭제되면 모든 요소 다 다시 index 설정해야 함.
under the hood
what is node in linked list
value + pointer
{
value = 4,
next = null
}
next는 어떻게 구현?
head ={
value = 6,
next = {
value = 4,
tail= next = null
}
}이런 식으로 되어있다고 생각하면 됨.
prepend
내 코드
public void prepend(int value){
Node newNode = new Node(value);
newNode.next=this.head;
this.head=newNode;
this.length++;
if(length == 1){
this.tail = this.head;
}
}
- 새로운 노드 생성
- 새로운 노드의 다음 노드로 지금의 head를 할당
- head에 새로운 노드 할당
- 리스트 길이 + 1
- 만약 리스트의 요소가 방금 추가한 노드밖에 없다면
- tail도 새로운 노드로 할당.
답
public void prepend(int value){
Node newNode = new Node(value);
if(length == 0){
this.head = newNode;
this.tail = newNode;
}else{
newNode.next=this.head;
this.head = newNode;
}
length++;
}
- 새로운 노드를 만든다
- 리스트에 아무것도 없을 경우 head와 tail에 새로운 노드를 할당한다.
- 리스트에 이미 하나라도 다른 요소가 있을 경우
- 새로운 노드의 다음 노드로 지금의 head를 할당
- head에 새로운 노드 할당
- 길이 + 1
별 차이 없어 보이지만 밑의 경우가 가독성이 더 좋고,
내 코드의 경우 newNode.next=this.head; 이 부분이 리스트에 아무것도 없을 때는 안 거쳐도 되는 코드인데 어떤 경우에도 다 거치게 되어있기 때문에 효율면에서도 큰 차이는 아니지만 떨어진다고 볼 수 있다.
remove first
내 코드
public Node removeFirst(){
Node toBeRemoved = this.head;
if(length > 0){
this.head = this.head.next;
length--;
if(length == 0){
tail = null;
}
}
return toBeRemoved;
}
- 삭제될 노드인 head를 변수를 만들어 저장해 놓는다.
- 리스트에 무언가 있어야 삭제가 가능하기 때문에 길이가 0보다 큰 경우에만 코드를 거친다
- head에 head의 다음 노드를 할당한다.
- 리스트의 길이를 줄인다.
- 만약 이제 요소가 없다면
- tail에 null을 할당해 준다. 그렇지 않으면 여전히 위에서 버린 head 노드를 가리키고 있을 거 기 때문
- 삭제될 노드가 저장된 변수를 리턴한다
2중 if문 별로라서 다시 해봄
public Node removeFirst(){
if(length == 0){
return null;
}
Node toBeRemoved = this.head;
this.head = this.head.next;
length--;
if(length == 0){
tail = null;
}
return toBeRemoved;
}
답코드
public Node removeFirst() {
if (length == 0) return null;
Node temp = head;
head = head.next;
temp.next = null;
length--;
if (length == 0) {
tail = null;
}
return temp;
}
오 거의 비슷함
근데 temp.next 에 왜 Null을 할당하는 거지?
아 연결되어 있는 걸 끊으려고 하는 거구나.
의문 2
temp.next = null; 의 위치.
temp를 할당하고 나서 바로 하면 안 되는 건가
//이렇게 말고
Node temp = head;
head = head.next;
temp.next = null; //!!
//이렇게하면 안되나?
Node temp = head;
temp.next = null; //!!
head = head.next;
안됨. 왜냐면.
2번째의 경우 head의 next가 null 이 되기 때문에
마지막 라인에서 원하는 대로 작동이 안 됨.
왜 그러냐면
객체는 참조타입이기 때문에 메모리 주소가 복사됨.
즉
- temp = head; ⇒ temp에 head가 저장되어 있는 메모리 주소저장
- temp.next = null; ⇒ head.next의 값을 null로 바꿈.
- head = head.next; ⇒ 위의 코드의 영향으로 head에 null이 할당됨
반면 처음 코드는
- 일단 temp에 head의 값이 저장된 메모리 주소가 저장됨
- head변수에 head.next 객체의 주소가 새롭게 할당됨. 위의 헤드와 빠이빠이임. 즉 이와 동시에 새로운 head의 next도 head.next.next로 바뀜.
- 이제 temp.next 의 변수에 null을 저장
아니근데 이렇게 되면 temp.next랑 head.next랑 같은데
두 번째에서 temp.next를 null로 바꾸면 head가 head.next가 된 거니까 얘도 null 되는 거 아님?
…?
아 아니지 위에서 temp.next 와 head.next는 진짜 걍 같은 객체인 거고
밑에는 그냥 같은 걸 가리키는 것뿐임
++
null
- there is only one null value in JVM. No matter how many variables refer to null.Object i = (Integer)null;
- System.out.println(s == i);//true
- Object s = (String)null;
https://stackoverflow.com/questions/2430655/java-does-null-variable-require-space-in-memory
Java - Does null variable require space in memory
Consider the following block of code: class CheckStore { private String displayText; private boolean state; private String meaningfulText; private URL url; public CheckStore(S...
stackoverflow.com
remove
나
public Node remove(int index){
if(index < 0 || index >= length) return null;
//해당 인덱스 노드 찾기
Node nodeTobeRemoved = get(index);
//임시저장
Node temp = nodeTobeRemoved;
//앞 뒤 연결 끊기
//처음꺼 삭제경우
if(index-1 < 0){
removeFirst();
}else if(index == length-1){
//마지막꺼 삭제경우
removeLast();
}else{
//중간삭제경우
get(index-1).next = nodeTobeRemoved.next;
length--;
}
//삭제노드 연결 끊기
nodeTobeRemoved.next=null;
//임시저장 return
return temp;
}
답
public Node remove(int index) {
if (index < 0 || index >= length) return null;
if (index == 0) return removeFirst();
if (index == length - 1) return removeLast();
Node prev = get(index - 1);
Node temp = prev.next;
prev.next = temp.next;
temp.next = null;
length--;
return temp;
}
- get 메소드는 o(n)이기 때문에 될 수 있으면 안 부르는 게 좋음.
Reverse
public void reverse(){
Node temp = head;
head = tail;
tail = temp;
Node after = temp.next;
Node before = null;
while(temp != null){
after = temp.next;
temp.next = before;
before = temp;
temp = after;
}
}
답
public void reverse() {
Node temp = head;
head = tail;
tail = temp;
Node after = temp.next;
Node before = null;
for (int i = 0; i < length; i++) {
after = temp.next;
temp.next = before;
before = temp;
temp = after;
}
}
- 의문
public void reverse() {
Node temp = head;
Node before = null;
head = tail;
tail = temp;
for(int i = 0; i < length; i++){
Node after = temp.next;//?
temp.next = before;
before = temp;
temp = after;
}
}
저기 반복문 안의 라인중에서 after = temp.next; 저게 왜 맨 위에 가야지만 하는 거지.
맨 밑으로 와도 상관없는 거 아닌가?
순서로 따지면 딱히 상관없는 거 아닌가.
응 아님
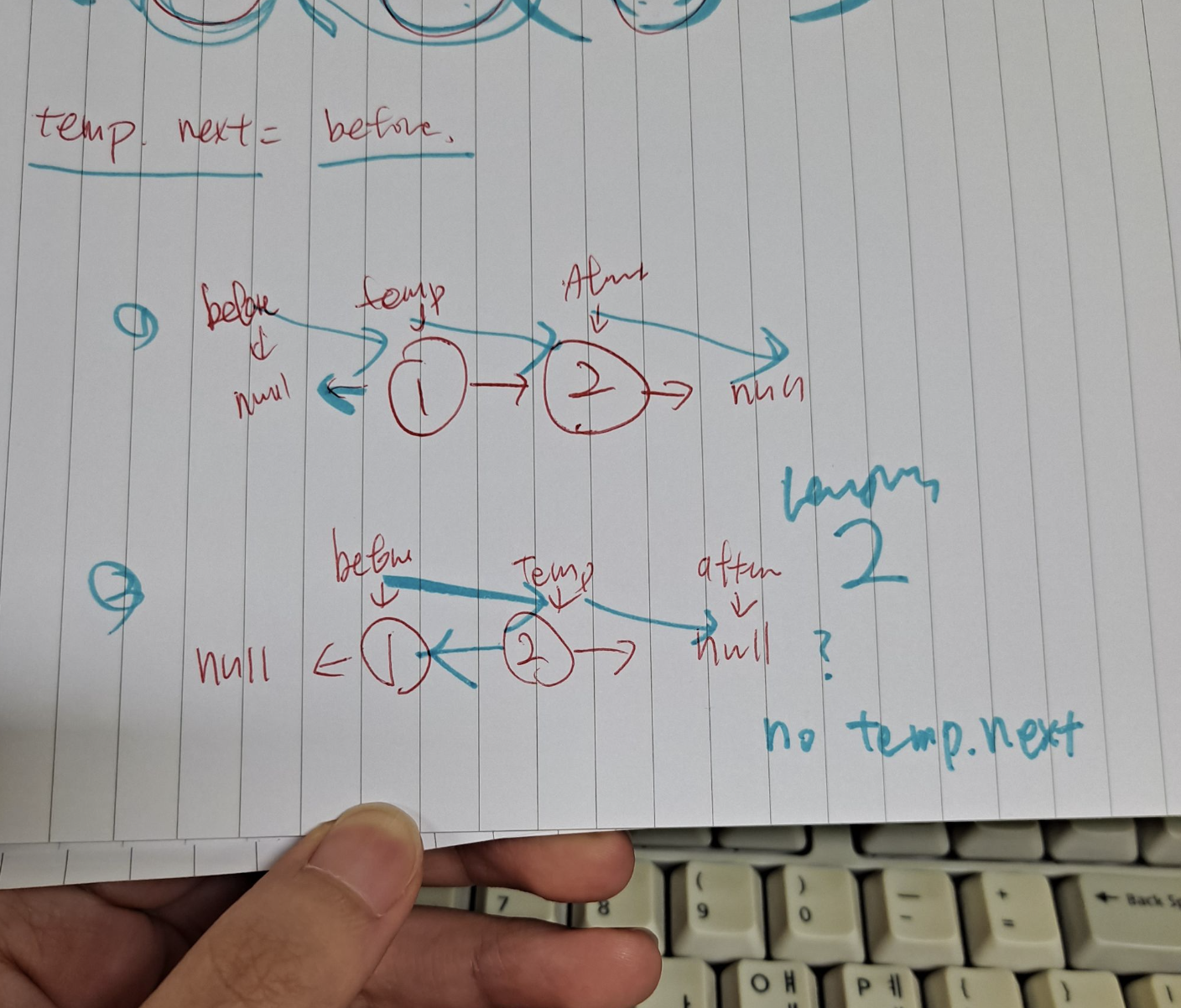
after = temp.next; 코드를 마지막에 둘 경우 반복문의 마지막 단계에서 temp = after을 거치면 temp가 null이 되는데 그다음에 after = temp.next를 수행하면,.,. null의 next를 구할 순 없음.
'study > Data structure' 카테고리의 다른 글
| Trees (0) | 2023.08.17 |
|---|---|
| stack and queue (0) | 2023.08.11 |
| Doubly linked list (0) | 2023.08.04 |
| classes & pointers (0) | 2023.07.21 |
| 빅오 Big(O) (0) | 2023.07.19 |




댓글